
We’ve written in the past how ESEF is a good step towards a digital future, but it’s by no means the “silver bullet” to improving the way listed businesses report their figures and, equally importantly, their story to the market.
One of the key challenges in ESEF’s practical implementation is undoubtedly the application of “extending and anchoring”. In the case where there’s no appropriate corresponding element in the base ESMA taxonomy (itself, based from the IFRS taxonomy), issuers can “extend” the taxonomy and create a new entity-specific tag or “extension”.
To avoid any reporting manipulation, ESMA requires each “extension” to be further anchored to the closest wider base element that’s already existing in the taxonomy.
Based on our research, 18% of ESEF data will generally need to be “extended and anchored”, which is around 40 figures per ESEF filing, on average. So, even though “extending and anchoring” have been introduced to prevent any reporting incomparability and data distortion in ESEF, there’s still room for discrepancies that might require some extra manual intervention by users.
The problem of comparing “extensions” in ESEF
Much work has been done by groups such as BP plc and Royal Dutch Shell plc to suggest how to compare data in extensions, when every extension is different. Let’s highlight the crux of the issue that they’re trying to resolve.
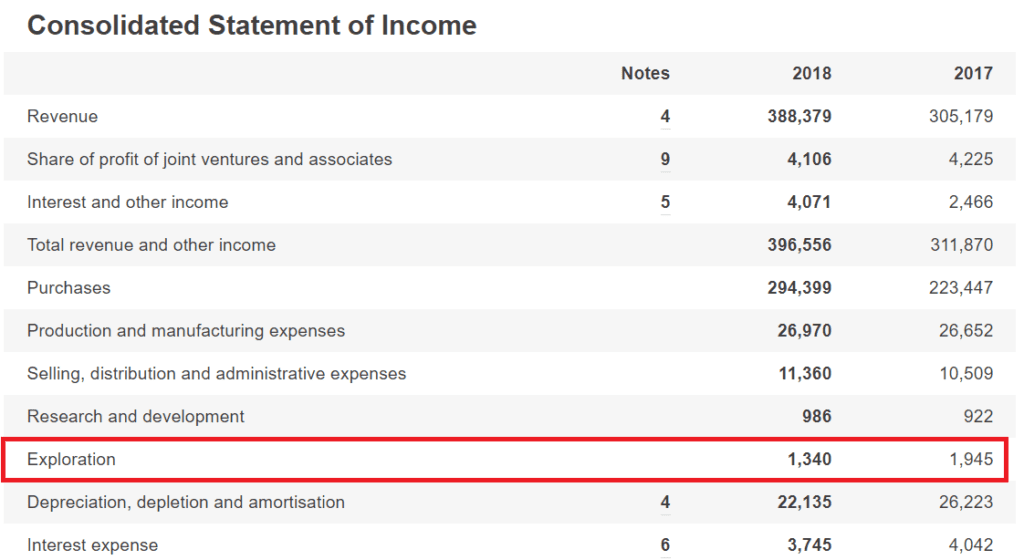
Company A – A large Oil & Gas listed business:
Company B – Another large Oil & Gas business:
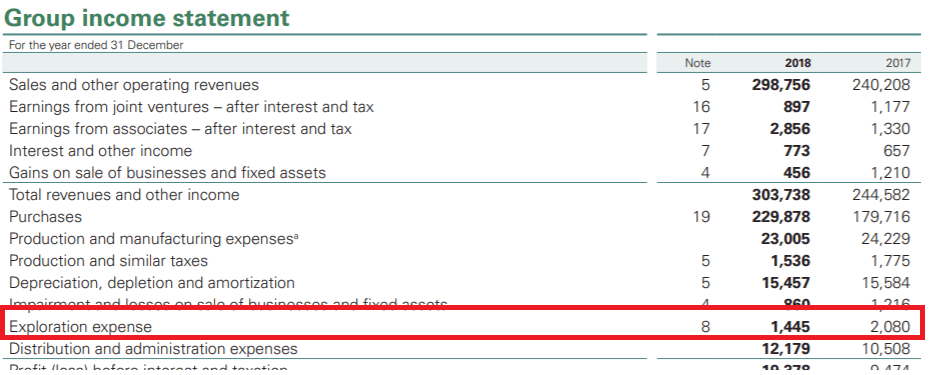
By looking at their Consolidated Income statement, we can see that both of them have lines or elements that very likely relate to the same kind of thing. However, because an equivalent tag doesn’t exist within the ESEF taxonomy, both firms will be required to extend and anchor that element.
What’s more annoying is that the extension tags will very likely be called “Exploration” in one instance and “Exploration expense” in another. The default will be to simply use the line item description as the name of the extension tag, which will automatically create data incomparability (unless somebody does some work somewhere to “tie” them together). A simple search for the word “Exploration” might reveal both items, but further would be needed to associate them with each other; hardly an automated way of comparing data.
Our solution
To solve that problem, our team have come up with quite a neat solution.
Because we tag everything from our Belfast office, we have a wealth of knowledge of how to tag accounts. We also have shared technology and shared expertise and experience. And what we’ll also have is a shared library of extensions.
In other words, as we begin to tag ESEF accounts “for real”, we’ll be creating a library of all extension tags that we apply. This will also help us understand what’s been seen before and collectively learn about what’s in accounts that isn’t in the ESMA taxonomy.
What this also means is that when we’re “extending and anchoring” for our clients, we’ll re-use tags from our library as far as possible. To the example above, if we’ve tagged “Client A” and added “Exploration Expense” to our library, then when we come to tag “Client B” we’d use that same extension. So, should the two datasets be analysed against each other, those two extensions would be identical, giving a little more comparability to the data.
If you’d like to find out more about our ESEF solutions, please get in touch.
